讲述elasticsearch的基本用法,包括创建库、建立倒排索引、排序规则、拼音搜索、地理位置搜索的基础实现。
初识
elasticsearch主要是倒排索引,通过将整个数据差分成关键字,建立以关键字为索引的表,加快我们对内容的一个搜索。简单来说就是把一整个文本差分成关键字,然后我们搜索关键字,找到这一文本。
这里只简单介绍一些常用的语法,具体可以参考官方文档[Quick start | Elasticsearch Guide 8.11] | Elastic
在使用elasticsearch之前需要先安装下载,如下。
Elasticsearch安装
这里使用docker来安装下载elasticsearch,关于docker的使用,可以参考其他docker命令教程,这里不在赘述。
-
首先在docker上面创建网络。
1
docker network create es-net
-
拉取elasticsearch镜像。
1
docker pull elasticsearch:8.11.1
-
创建挂载点目录,并修改目录权限
1
2
3
4
5mkdir -p /usr/local/es/data /usr/local/es/config /usr/local/es/plugins
chmod 777 /usr/local/es/data
chmod 777 /usr/local/es/config
chmod 777 /usr/local/es/plugins -
部署单点es,创建es容器。
1
2
3
4
5
6
7
8
9
10
11
12docker run -d \
--restart=always \
--name es \
--network es-net \
-p 9200:9200 \
-p 9300:9300 \
--privileged \
-v /usr/local/es/data:/usr/share/elasticsearch/data \
-v /usr/local/es/plugins:/usr/share/elasticsearch/plugins \
-e "discovery.type=single-node" \
-e "ES_JAVA_OPTS=-Xms512m -Xmx512m" \
elasticsearch:8.11.1命令解释:
-
--name es:设置集群名称 -
-e "ES_JAVA_OPTS=-Xms512m -Xmx512m":内存大小 -
-e "discovery.type=single-node":非集群模式 -
-v /usr/local/es/data:/usr/share/elasticsearch/data:挂载逻辑卷,绑定es的数据目录 -
-v /usr/local/es/plugins:/usr/share/elasticsearch/plugins:挂载逻辑卷,绑定es的插件目录 -
--privileged:授予逻辑卷访问权 -
--network es-net:加入一个名为es-net的网络中 -
-p 9200:9200:端口映射配置
-
-
修改elasticsearch配置文件,将远程连接验证关闭掉。
1
2
3docker exec -it es /bin/bash
cd config
echo 'xpack.security.enabled: false' >> elasticsearch.yml -
重启服务,访问elasticsearch的端口地址,结果如下,则启动成功。
1
docker restart es
kibana安装
图形化使用Elasticsearch。
-
拉取Kibana镜像。
1
docker pull kibana:8.11.1
-
部署Kinana,创建Kinana容器。
1
2
3
4
5
6
7docker run -d \
--restart=always \
--name kibana \
--network es-net \
-p 5601:5601 \
-e ELASTICSEARCH_HOSTS=http://es:9200 \
kibana:8.11.1命令解释:
--network es-net:加入一个名为es-net的网络中,与elasticsearch在同一个网络中-e ELASTICSEARCH_HOSTS=http://es:9200":设置elasticsearch的地址,因为kibana已经与elasticsearch在一个网络,因此可以用容器名直接访问elasticsearch-p 5601:5601:端口映射配置
安装IK分词器
IK分词是支持中文分词的插件。
-
进入容器内部。
1
docker exec -it es /bin/bash
-
在线安装IK分词器。
1
./bin/elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v8.11.1/elasticsearch-analysis-ik-8.11.1.zip
索引库操作
索引库操作相对对数据库的表的操作,存储数据之前要先创建库和表。
Mapping映射属性
Mapping对索引库的文档约束。
常见属性:
-
type:字段的数据类型,常见的有:
- 字符串:text(可分词的文本),keyword(精确值)
- 数值:long、integer、short、byte、double、float
- 布尔:boolean
- 日期:date
- 对象:object
对于数组只看器元素是什么类型。
-
index:指定字段是否创建索引。
index=true 表示字段创建索引 -
analyzer:指定使用那种分词器,针对text可分词文本使用
-
properties:该字段的字段(对象类型)
创建索引库
相对于建立一张表,对字段进行类型定义,是否创建索引,指定使用分词器类型等操作,示例:
1 | PUT /索引库名称 |
在properties属性中定义字段,字段中定义数据类型,是否建立索引,采用什么分词器。
如果中还有其他字段,该字段也能够定义properties属性。
实际搜索,我们可能是对多个字段内容进行搜索,为了加快搜索效率,我们可以将参与搜索的字段整合在一起。
示例:
1 | PUT /索引库名称 |
我们再定义一个字段all,将参与搜索的字段都加上"copy_to": "all",相当于绑定到all这个字段上,最后我们只需要对all这个字段进行全文搜索,就可以实现对多个字段进行搜索。all字段也要指定分词器。
查询索引库
语法如下:
1 | GET /索引库名 |
修改索引库
索引库核心就是索引的数据结构,一旦改变就需要重新创建倒排索引。索引库一旦创建就无法修改mapping。
虽然无法修改mapping中已有的字段,但允许添加新字段到mapping中,不会对倒排索引产生影响。
添加字段语法如下:
1 | PUT /索引库名/_mapping |
和创建的请求方式不同,数据定义的方式是相同的。
删除索引库
语法如下:
1 | DELETE /索引库名 |
文档操作
新增文档
数据库中insert语句,来添加数据。语法如下:
1 | POST /索引库名/_doc/文档id |
查询文档
这里简单介绍查询,查询作为索引库的主要功能在DSL重点讲解。
1 | GET /{索引库名称}/_doc/{id} |
删除文档
语法:
1 | DELETE /{索引库名}/_doc/id值 |
修改文档
修改文档有两种方式:
- 全量修改:直接覆盖原来的文档
- 增量修改:修改文档的部分字段
全量修改
全量修改的本质是删除指定id的文档,新增一个相同的id的文档。
如果根据id删除时,id不存在,直接执行新增。
语法:
1 | PUT /{索引库名}/_doc/文档id |
语法和新增文档的语法一样。
增量修改
增量修改只修改指定id匹配的文档中部分字段。
语法如下:
1 | POST /{索引库名}/_update/文档id |
DSL查询文档
DSL查询分类:
- 查询所有:
match_all - 全文检索:利用分词器对用户输入的内容进行分词,然后去倒排索引库中匹配。
- 精确查询:根据精确词条值查找数据。
- 地理查询:根据经纬度查询。
- 复合查询:将上述各种查询条件组合起来,合并查询条件。
查询语句基本一致:
1 | GET /indexName/_search |
全文检索
全文检索基本流程:
- 对用户搜索内容进行分词,等到搜索词条
- 根据词条去倒排索引库中匹配,得到文档id
- 根据文档id找到文档,返回给用户
基本语法
- match查询:单个字段查询
- multi_match查询:多字段查询,任意一个字段符合要求就算符合查询条件
match查询语法
1 | GET /indexName/_search |
multi_match查询语法
1 | GET /indexName/_search |
精确查询
精确查询一般是查找keyword,数值,日期,boolean类型字段。不会对搜索条件分词。
基本语法
两种实现方式:
-
term查询
精确查询的字段是不分词的字段,因此查询的条件也必须是不分词的词条。
查询时,用户输入的内容和自动值完全匹配时才认为符合条件。
-
range查询
范围查询,一般应用在对数值类型做范围过滤。
term查询语法
1 | GET /indexName/_search |
range查询语法
1 | GET /indexName/_search |
地理查询
根据经纬度查询,官方文档[Geo queries | Elasticsearch Guide 8.11] | Elastic
矩阵范围查询
查询时,需要指定矩形的左上、右下两个点的坐标,然后画出一个矩形,落在该矩形内的都是符合条件的点。
基本语法
1 | GET /indexName/_search |
附近查询
查询到指定中心点小于某个距离值的所有文档。
基本语法
1 | GET /indexName/_search |
复合查询
复合查询将其他简单的查询组合起来,实现更复杂的搜索逻辑。
常见两种:
- function score:算法函数查询,可以控制文档排名
- bool query:布尔查询,利用逻辑关系组合多个其他查询,实现复杂搜索
相关性算分
进行文档搜索时,文档结果会根据搜索词条的关联度打分,返回结果时按分值降序排列。
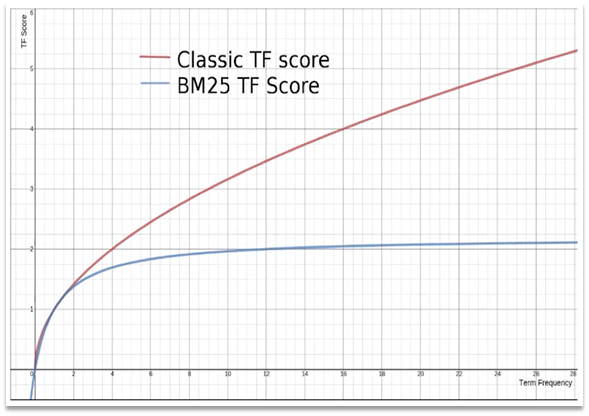
Elasticsearch中早期使用的打分算法是TF-IDF算法,公式如下:
$$
TF(词条频率)=\frac{词条出现次数}{文档中词条总数} \
IDF(逆文档频率)=\log(\frac{文档总数}{包含词条的文档总数}) \
socre = \sum_{i}^{n}TF(词条频率)\times IDF(逆文档频率)
$$
在5.1版本之后,改用了BM25算法,公式如下:
$$
Socre(Q,d)=\sum_{i}^{n}\log(1+\frac{N-n+0.5}{n+0.5})\cdot\frac{f_i}{f_i+k_i\cdot(1-b+b\cdot\frac{dl}{avgdl}}
$$
TF-IDF算法缺陷,词条频率越高,文档得分也会越高,单个词条对文档影响较大。而BM25则会让单个词条的算分有个上线。
基础语法
1 | GET /your_table_name/_search |
-
原始查询条件:query部分,基于这个条件,并且基于BM25算法给文档打分,原始算分。
-
过滤条件:filter部分,符合该条件的文档才会重新算分。
-
算法函数:根据这个函数做运算,得到函数算分。
四种函数:
- weight:函数结果是常量
- field_value_factor:以文档的某个字段值作为函数结果
- random_score:以随机数作为函数结果
- script_score:自定义算分函数算法
-
运算模式:算分函数的结果,原始查询的相关性算分,两者之间的运算方式
包括:
- multiply:相乘
- replace:用算分函数的score替换原来的score
- 其他:sum、avg、max、min
function_score算分流程:
- 根据原始条件查询搜索文档,并且计算相关性算分,得到原始算分
- 根据过滤条件,过滤文档
- 符合过滤条件的文档,基于算分函数运算,得到函数算分
- 将原始算分和函数算分基于运算模式做运算,得到最终结果,作为相关性算分
布尔查询
布尔查询时一个或多个查询字句的组合,每一个子句就是一个子查询。子查询的组合方式有:
- must:必须匹配每个子查询,类似“与”
- should:选择性匹配子查询,类似”或“
- must_not:必须不匹配,类似”非“
- filter:必须匹配,不参与算法
需要注意的是,参与打分的字段越多,查询的性能也越差。建议:
- 搜索框关键字采用全文检索,使用must查询,参与算法
- 其他过滤条件,采用filter查询,不参与算分。
基本语法
1 | GET /your_table_name/_search |
搜索结果处理
排序
指定排序条件,处理返回结果的顺序。
普通字段排序
1 | GET /indexName/_search |
如果有多个字段参与排序,是按照写的字段先后排序,先根据第一个字段排序,然后根据后面的字段排序。
这里sort是对最后结果进行排序,而之后的order是对相关字段进行排序。如果指定sort,原来的算法排序会被取代,这里通过将_score字段加上,实现原算分排序。
地理坐标排序
1 | GET /indexName/_search |
指定一个坐标作为目标点,计算文档中字段到目标点距离大小,根据距离排序。
分页
elasticsearch 默认情况下只返回top10的数据。而如果要查询更多数据就需要修改分页参数了。elasticsearch中通过修改from、size参数来控制要返回的分页结果:
- from:从第几个文档开始
- size:总共查询几个文档
基本分页
1 | GET /hotel/_search |
深度分页
问题说明:如果要查看第990开始的数据,Elasticsearch内部分页时,是先查询0-1000条的数据,然后截取其他的990-1000这10条数据。也就是查深度越大的数据,其实是把前面所有数据都要查出来,然后截取。传统的分页方式会导致性能问题,因为每次查询都需要重新计算和加载数据,对CPU和内存会产生非常大的压力,因此elasticsearch会禁止from+ size 超过10000的请求。
针对深度分页常用的一种解决办法是采用滚动查询的方式,
-
在初始搜索请求,设置一个scroll参数指定滚动的保持时间,这个时间就是初始搜索请求和结果缓存保留时间。
第一次搜索:
1
2
3
4
5
6
7POST /index/_search?scroll=1m
{
"size": 100, // 每次返回的文档数量
"query": {
// 查询条件
}
} -
搜索返回的结果会返回一个
_scroll_id值,这个值是上一次搜索返回结果的末尾位置,在下次搜索,通过传递这个_scroll_id值,从上次搜索结束的位置向后搜索,滚动查询。后续搜索(不用再指定搜索条件了,第一次结果已经保留,只要向后继续取数据)
1
2
3
4
5POST /_search/scroll
{
"scroll": "1m",
"scroll_id": "_scroll_id"
} -
之后的搜索重复上一步,直到获取到所有需要的数据或者滚动查询的时间窗口过期。
高亮
高亮的原理就是在搜索的关键字前后加上前端的标签,使得在网页页面上可以高亮显示。
通过标签在前端渲染得到的高亮效果。
实现:
1 | GET /your_table_name/_search |
注意:
- 高亮是对关键字高亮,因此搜索条件必须带有关键字,而不能是范围这样的查询。
- 默认情况下,高亮的字段,必须与搜索指定的字段一致,否则无法高亮
- 如果要对非搜索字段高亮,则需要添加一个属性:required_field_match=false
数据聚合
聚合可以实现对数据的统计、分析、运算等,实现统计功能比数据库SQL方便、而且查询速度快,可以实现实时搜索效果。
聚合种类
聚合常见三类:
- 桶(Bucker)聚合:对文档进行分组,类似于MySQL的
group by - 度量(Metric)聚合:进行计算,例如求和、平均值、最小值、最大值等,类似于MySQL中聚合函数
- Avg:平均值
- Max:最大值
- Min:最小值
- Stats:同时求max,min,avg,sum等
- 管道(pipeline)聚合:其他聚合的结果为基础做聚合
注意:参加聚合的字段必须是keyword、日期、数值、布尔类型(不可分)
Bucker聚合
1 | GET /indexName/_search |
aggs:代表聚合,与query同级,query的作用限定聚合的文档范围- 聚合三要素:聚合名称、聚合类型、聚合字段
- 聚合可配置属性:
size指定聚合结果数量,order指定聚合结果排序,field指定聚合字段
Metric聚合
这个基于在桶聚合的基础上使用的聚合,是对桶内数据进行运算,相当于MySQL中having语句的作用。
这个聚合也是直接写在桶内聚合里面的。
基本语法如下:
1 | GET /indexName/_search |
自动补全
搜索时提示出与该字符有关的搜索项。
拼音分词器
下载拼音分词器,可以实现中文拼音自动补全功能。
下载地址:拼音分词器|官方文档)
下载方式和之前IK分词器下载步骤一样:
-
进入容器内部。
1
docker exec -it es /bin/bash
-
在线安装拼音分词器。
1
./bin/elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-pinyin/releases/download/v8.11.1/elasticsearch-analysis-pinyin-8.11.1.zip
通过指定分词器即可使用。
自定义分词器
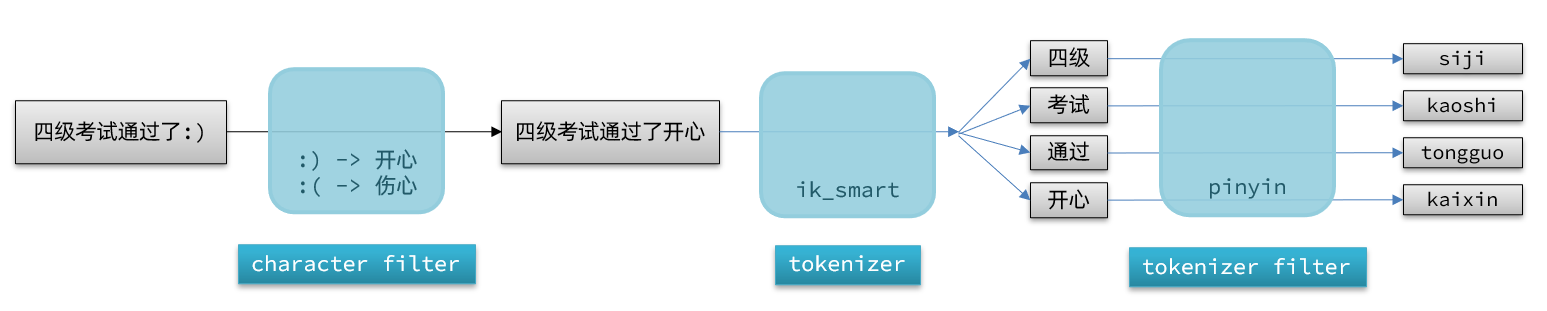
默认的拼音分词器会将每个汉语单独分为拼音,但实际使用希望是每个词条形成一条拼音,我们需要单独做个性化设置,形成自定义分词器。简单来说就是组合使用多个分词器,实现一些分词效果。
Elasticsearch中分词器分为三部分:
- character filter:tokenizer之前对文本进行处理。例如删除字符、替换字符等。
- tokenizer:将文本按照一定的规则切割成词条。
- tokenizer filter:将tokenizer输出的词条做进一步处理。例如大小写转换,同义词处理、拼音处理等。
处理流程类似于:
自定义分词器语法:(创建索引库阶段设置)
1 | PUT /indexName |
使用拼音分词器需要注意的在搜索时不要使用,避免搜索到同音字,所以在设置字段的时候就要指定什么时候使用那种分词器。
自动补全查询
Elasticsearch提供了[Suggesters | Elasticsearch Guide 8.11] | Elastic| Completion Suggester 查询实现自动补全功能。
这个查询会匹配用户输入内容开头的词条并返回。为了提高补全查询的效率,对于文档中字段的类型约束:
- 参与补全查询的字段必须是completion类型。
- 字段的内容一般是用来补全的多个词条形成的数组。
对于自动补全代码,需要在创建索引表对字段进行定义,内容是以数组形式传递。
1 | PUT /indexName |
搜索基础语法:
1 | GET /indexName/_search |